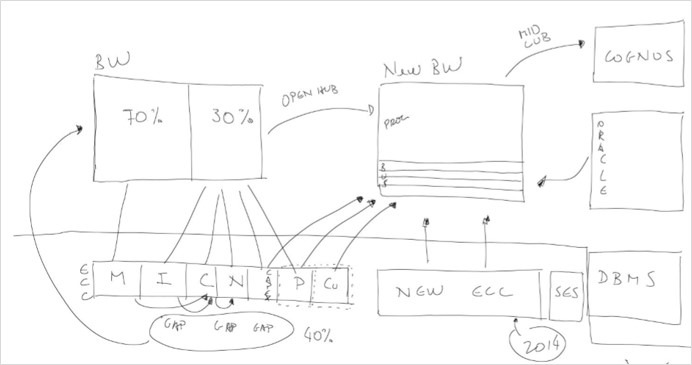
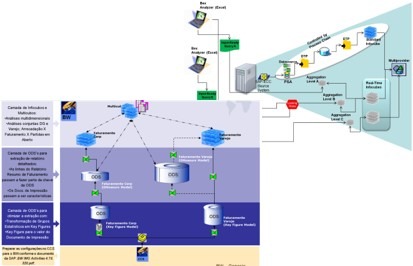
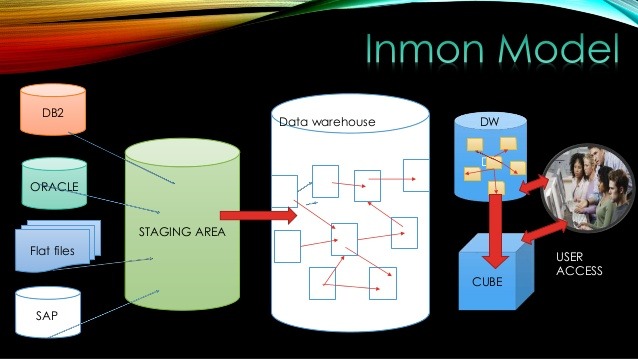
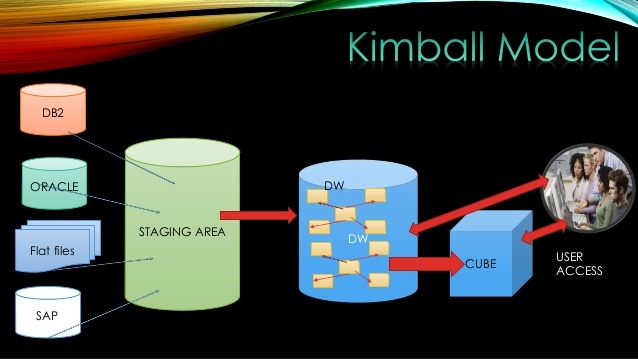
The Enterprise Analytical Environment, a flexible, time-to-market driven and governed approach
Once a corporation has an appropriate BI & Analytics maturity level defined and the drivers to guide her to an Agnostic Informational Architecture, it is possible to detail this architecture. However, we must always have in mind that “It is not all about data, it is all about business”.
Therefore, besides the drivers I listed and detailed in a previous article in this blog, the capacity of providing an ever-low time-to-market for informational solutions must pervade every single component of the architecture. Thus, I propose a generic framework to be adopted as the Enterprise Analytical Environment.
Before presenting it, we must discuss a little bit about the “time-to-market” of informational solutions. The recurrent incapacity to deploy informational solutions in a timely manner is the major complaint of reporting users, and the top reason for the proliferation of Excel spreadsheets all around the corporation, creating data silos. The new tools for big data and analytics are being sold now as the redemption for the business users, so they can finally have everything they always wanted and needed in a very simple and fast way. One of the big hurdles for this dream to become true is the emerging Data Swamps instead of the aimed Data Lakes. For a deeper discussion about this, I recommend an excellent article written by Daniel Sholleri at Colibra.com Daniel clarifies the many questions of the discussion:
“But because the economics of the data lake are so compelling, organizations have often begun by putting data into the lake without clear information about what currently exists”. This creates two outcomes:
1. The data in the lake is only usable by those who already knows what it is and what it means. If different users have access to the same data, they will create a replica and label it differently. The lake then becomes a silo, in which the shared infrastructure does not result in information sharing. At the end, copies tends to proliferate due to low additional storage cost.
2. As stored information becomes a babel tower, it is a herculean task to distinguish the data in the lake. And sadly, instead of at least organized and manageable swamp it turns into a pit of mud. One would not be able to separate the husk from the grain.
https://www.collibra.com/blog/blogdata-lake-vs-data-swamp-pushing-the-analogy/
Taking all this into account, I want to highlight another aspect of this anxiety for fast access to informational solutions and the use of the Data Lake as a solution. Blame the tools, IT professionals and governance for slow time-to-market of informational solutions. Imagining that a proper Data Lake will be conceived and built by end-users and good big data, data viz or other statistical tool is as naive as sailors charmed by mermaids. Software and hardware firms have excellent technical sellers whose chants are more effective than Calypso’s strategies to hold back Ulysses. Mythological metaphors aside, the thing is: businesses will not get rid form IT, an IT must have ways to deliver fast without putting corporate information at risk or let everything becoming messy.
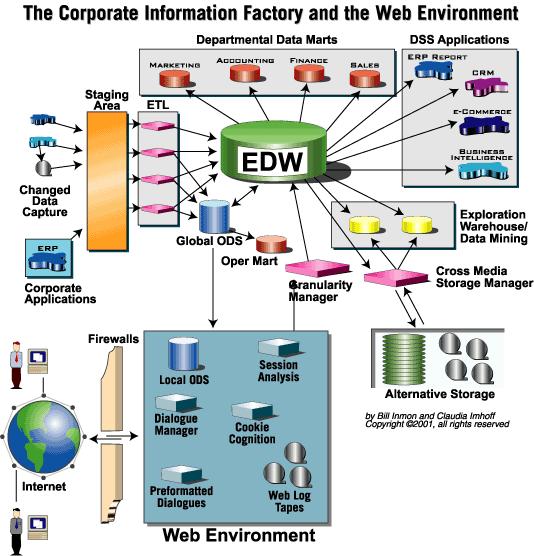
What I advocate is an Enterprise Analytical Environment based in few obligatory components/layers, but well organized, easily and flexibly governed. This conceptual framework has 4 components with a set of layers in each of them. These layers provide more organization to the environment. Also none of the components/layers obligates data persistence or replication; they can be just a pass-thru to provide governance and usage track in some cases.
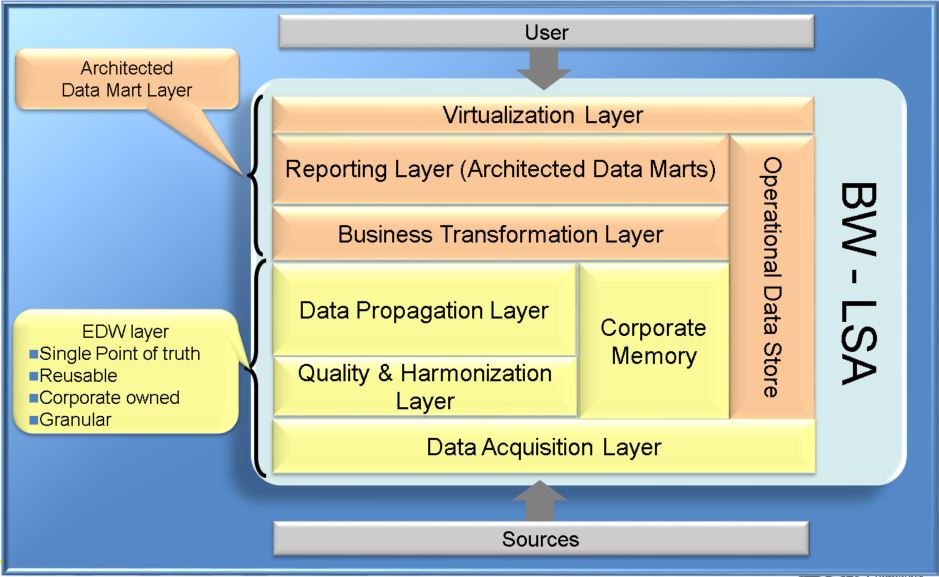
 At this point, it is also noteworthy that it is not 100% clear what will happen to the EDW concept. If it will be incorporated by the advanced analytics/data lake, or if they will coexist architecturally speaking. A simplification could bring the EDW to become a layer of the advanced analytics component of the framework. For now, I’d rather represent it in a coexistent with an intersection area of them both, that can or not be merged in the future. That is why I choose to use a 3D figure to present the conceptual model where I can represent better this concepts being merged with an intersection area.
At this point, it is also noteworthy that it is not 100% clear what will happen to the EDW concept. If it will be incorporated by the advanced analytics/data lake, or if they will coexist architecturally speaking. A simplification could bring the EDW to become a layer of the advanced analytics component of the framework. For now, I’d rather represent it in a coexistent with an intersection area of them both, that can or not be merged in the future. That is why I choose to use a 3D figure to present the conceptual model where I can represent better this concepts being merged with an intersection area.
The components and layers of the proposed Enterprise Analytical Environment are described below:
But how actually can data/information be treated, used and published?
For this, I should say that there are three alternatives that are closely related to the need of data/information percistence. If the informational solution requires intense/frequent, complex and stable transformations of considerable amount of data, it is advisable to use the “Schema on Write” persisting the data/information.
On the other hand, if the rules to be applied requires frequent changes, the “Schema on Read” shall be adopted and no persistence (or minimal) is recommended. But, if a very little transformation is to be applied, then “Data Consumption”, also with no persistence (or minimal), is probably the best option.
So, it is important to provide a logical model of the conceptual architecture in a 2D representation, where these three alternatives appear in possibilities of data flows.
The proposed framework also enables a simplified and flexible governance, through a quadruple segmentation:
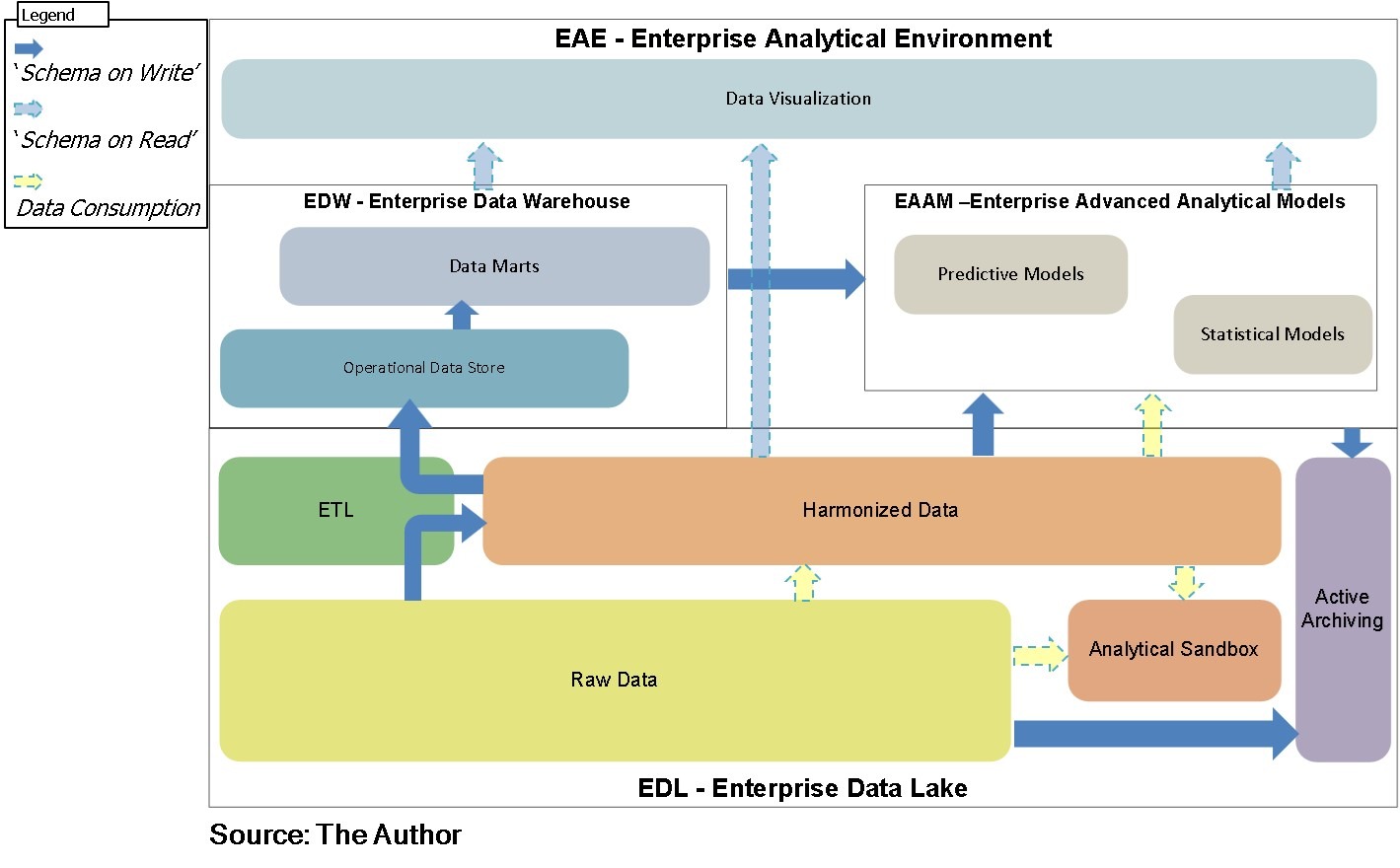
- The Enterprise Data Lake (EDL);
- The Enterprise Data Warehouse (EDW);
- The Enterprise Advanced Analytical Models (EAAM); and
- The Data Visualization.
This segmentation would ensure compliance within given safety standards and enable information democratization. Are we or aren’t we in the information age?
But segmentation shall be based on the concept of “content areas”, which are logical and physical grouping of data and information. There are three types of content area: Data Content Area (DCA), Information content area (ICA), and Master Data Content area (MCA). Each content area can have a different governance and ownership.

The rest is naming convention and specific technical standards of each tool. Yet, all of this can be interpreted as the “IT Structure” holding back the business with rules, standards, layers, etc.
But taking a closer look at the arrows that represent how data/information can be acquired, “digested”, used and published, if appropriate framework is in place, informational solutions can be delivered very quickly.
Suppose that the “power user” (best case with a data scientist support) that will have access to the “Analytical Sandbox” defines a data set from specific “Raw Data” and have the KPIs and the type of predictions they want. As soon as they feel comfortable with the model, this can be deployed and published within the proper DCA/ICA. The critical success factors of this approach are: power user’s knowledge, and an agile and simplified infrastructure and landscape (best case DevOps).
Of course, not all corporations are ready for this approach, but companies should definitely set it as a target for its IT strategy. One can also not forget that there should be a balance between IT knowledge experts and “power users”.
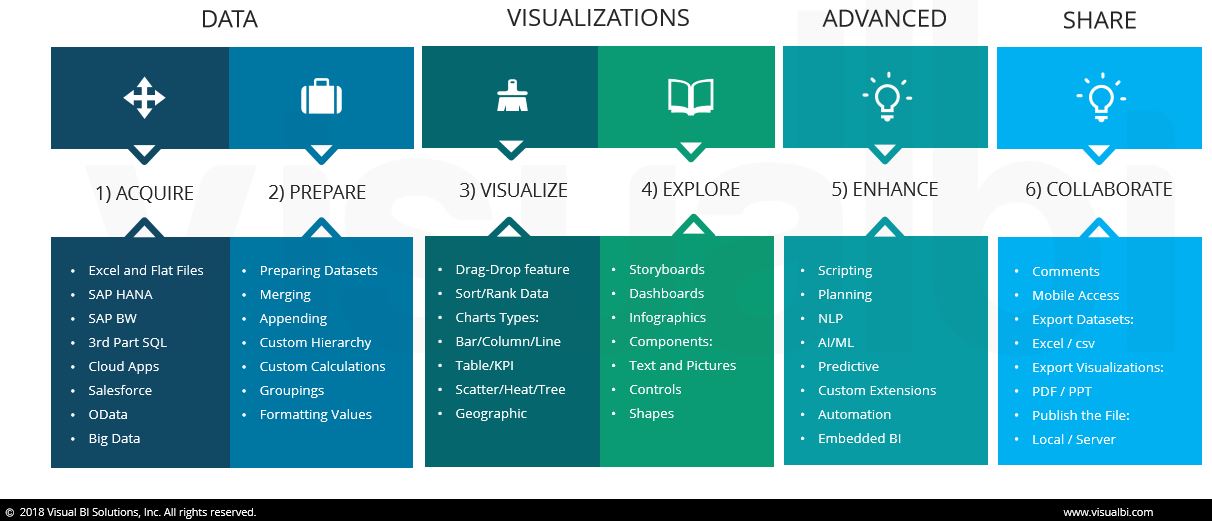
This balanced situation will also drive the choice of the best fit data visualization tool. An excellent and extensive study has been presented by Arun Varadarajan and Gopal Krishnamurthyii. In an in-depth comparison, they both evaluated the Visual BI and Self Service BI tools and proposed an evaluation criteria to provide guidance depending on power-users independence, as well as the BI & Analytics Maturity Level of organizations.
http://visualbi.com/blogs/data-discovery/self-service-bi-tools-comparison-tableau-power-bi-qlik-spotfire-sap-lumira-sap-analytics-cloud/
In sum, the Enterprise Analytical Environment I propose here is flexible, time-to-market enabled, well organized and end-user driven. It is not a matter of not listening to the several charming and “built to suit” IT sales pitch. It is a matter of getting to know better what you want, honestly assess how is your data, and take some time to detail the specificities of your company and implement the Enterprise Analytical Environment.
In the next posts, I will discuss how to “brand” the Agnostic Informational Architecture and how to create a roadmap to deploy the Enterprise Analytical Environment.
_______________________
i https://www.collibra.com/blog/blogdata-lake-vs-data-swamp-pushing-the-analogy/